We leverage the elegance of kdb+ and the power of Rust to create data applications that can process data at the rate of tens of GB/second on consumer grade hardware.

At Red Sift, we use our platform to power next-generation data applications for cybersecurity. At a high level, our platform is one of those trendy serverless compute environments except ours allows you to get real work done. Red Sift lets us pipe data around, transform/augment it and finally aggregate it to find insight that helps keep organisations and individuals safe. All of these features come with the required scaffolding to build real-world cloud SaaS applications. We are talking about keyed APIs, web interfaces, role-based permissions – all critical for the enterprise-grade software we provide for some of the largest organizations in the world. One of the coolest features of the platform is the ability to integrate different technology components into a single application with no glue code. Using this capability, we recently added kdb+ to our core platform as we are building a new cybersecurity product that relies heavily on processing time series data.
First, a little bit on kdb+. You can think of it as a platform to build your own database using a box of powerful primitives. While this sounds complex, kdb+ and the driving language q make it relatively painless. The main advantage is total control over the layout and access patterns both in memory and once you have splayed the data to your storage medium of choice. This control allows you to unlock staggering performance which is why kdb+ is used extensively across sectors such as financial services, where latency (the only hard problem in computer science) translates to big bucks.
Next, Rust. We use Rust in the software agent for our new IDS product so we started to experiment with it for use in our data pipeline too. Rust is a tremendously sophisticated language that is having a bit of a moment in part due to its adoption in the new Firefox. In Mozilla’s browser it is now replacing some of the hairiest bits of the browser and unlocking market leading performance. Rust is built on the LLVM toolchain which gives it some of the highest quality native code generation on the market. Also critically, for what we are about to do with it, it provides compatibility with C memory layout and calling conventions. This is a big deal as we often run into this limitation with our other systems level programming language of choice.
You use kdb+ when you need the fastest solution, so we posed the question: How fast can you go? When we combine these 2 bits of technology, we can build a time series data stack on steroids. While the full technical detail is beyond the scope of a blog post, we have just open sourced a small but useful binding that gives us access to modern hashing functions in q.
Hash++ : Adding a simple extension
One operation we end up doing a lot of is hashing. We need to generate identity functions for the data we ingest so we can aggregate and search in an efficient manner across multiple fields. Out of the box, q supports the good old MD5 hash but we can do better.
We are looking for a non-cryptographic hash and I am particularly fond of the smhasher library as it includes a hardware accelerated version of MetroHash. Specifically it includes an SSE4.2 implementation on modern x86 processors that can truck along at many GB (that is bytes, not bits)/s. We wanted to plug this into kdb+ via Rust and were keen to see if we could realize some of this performance in the real world.
We have created a small Rust library that maps to and from kdb+ types. It includes a .q file that links in the Rust functions that have been exported with C calling conventions and a few tests and benchmarks.
Our binding creates 2 new hash functions based on the 64 bit (rmetro64) and 128 bit (rmetro128) variant of the Metro hash that can be called by q in a manner mostly compatible with the inbuilt MD5 implementation.
[shell] KDB+ 3.6 2018.06.14 Copyright (C) 1993-2018 Kx Systemsm64/ 12()core 16384MB
q)\l krs-hash.q
q)md5 “hello world”
0x5eb63bbbe01eeed093cb22bb8f5acdc3
q)rmetro128 “hello world”
32bd829a-47d0-8cb3-3b25-9bfbdfc07543
[/shell]
Note that the 128bit version of rmetro returns the value of the hash as a native q type GUID for easier comparison and ranging. The inbuilt MD5 can be coerced into a compatible return type using the following:
[shell] q)/ turn the byte sequence into a GUID using svq)0x0 sv md5 “hello world”
5eb63bbb-e01e-eed0-93cb-22bb8f5acdc3
[/shell]
How fast?
We can quickly generate some dummy data with a q script and test a few scenarios. [shell]q krs-hash-dict-bench.q[/shell] tests some dictionary transformations before hashing the entire thing.
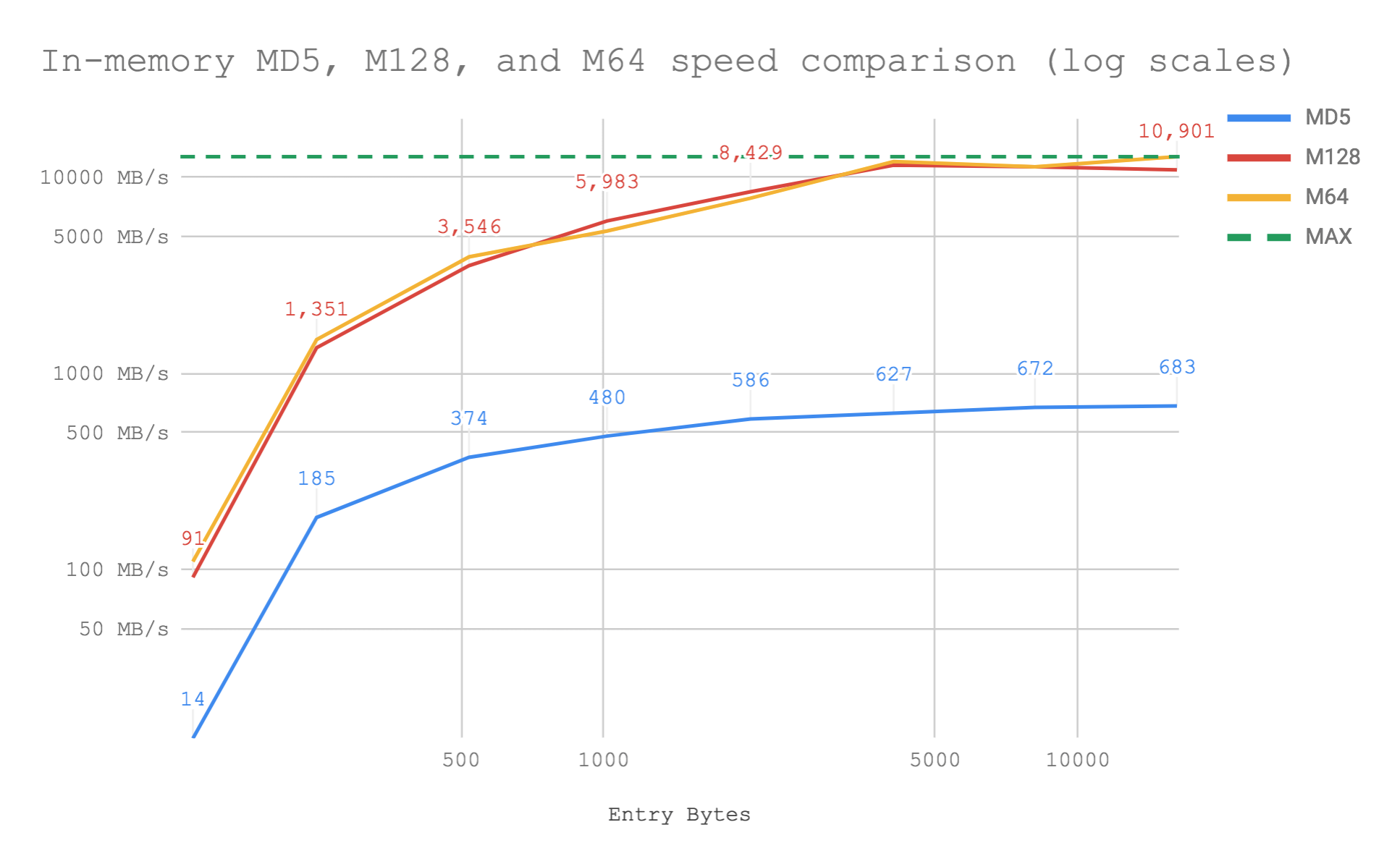
i7-8750H CPU @ 2.20GHz on macOS
The modern hashing implementation in Rust is between 8x and 18x faster than the built-in MD5 and is just as easy to use. The performance difference grows as the size of data being hashed increases as one would expect. The hot loop in the Metro hash is tightly optimised and amortises the small but present cost of calling into the library and the associated bindings. We are shifting close to 11GB/s at the larger parameter sizes. A simpler in memory string hash, also in the repository, will peak at 16GB/s for the 64 bit hash on the same hardware.
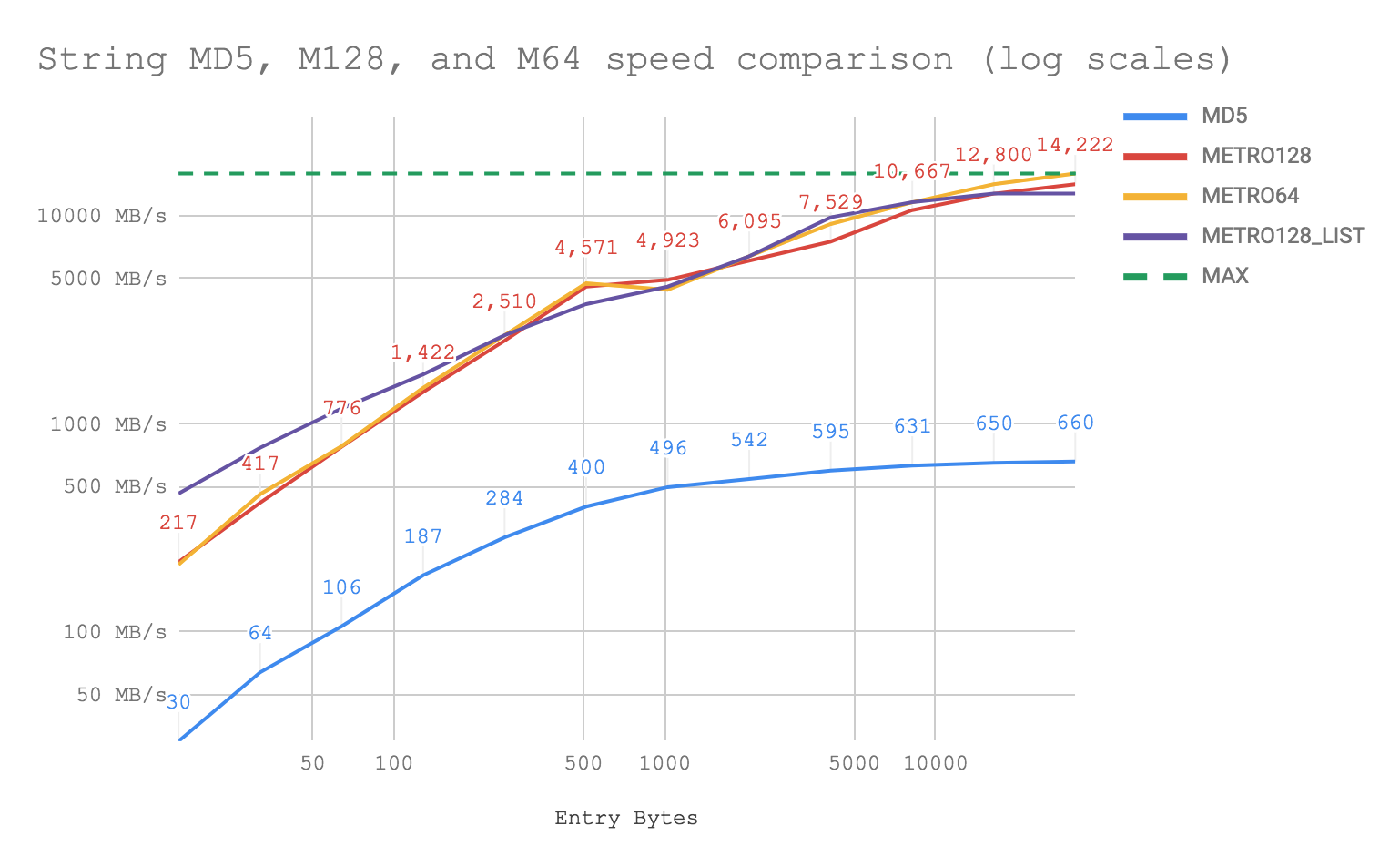
i7-8750H CPU @ 2.20GHz on macOS
This version also tests a variant of the 128 bit hash that operates directly on q MixedLists and emits a list of GUIDs plotted here as METRO128_LIST. At small sizes, this approach is useful as it reduces the cost of invocation though memory overheads are higher.
At those speeds, we are within throwing range of the maximum memory bandwidth of the DDR4 memory on my test machine. 2.4Ghz memory * 2 memory channels * 8 bytes (64 bits) per clock = 38.4GB/s is as fast as I could possibly go if I was just copying large buffers around.
We can make this more complex by getting q to create hashes from dictionary content that is paged-in from a memory mapped Anymap.
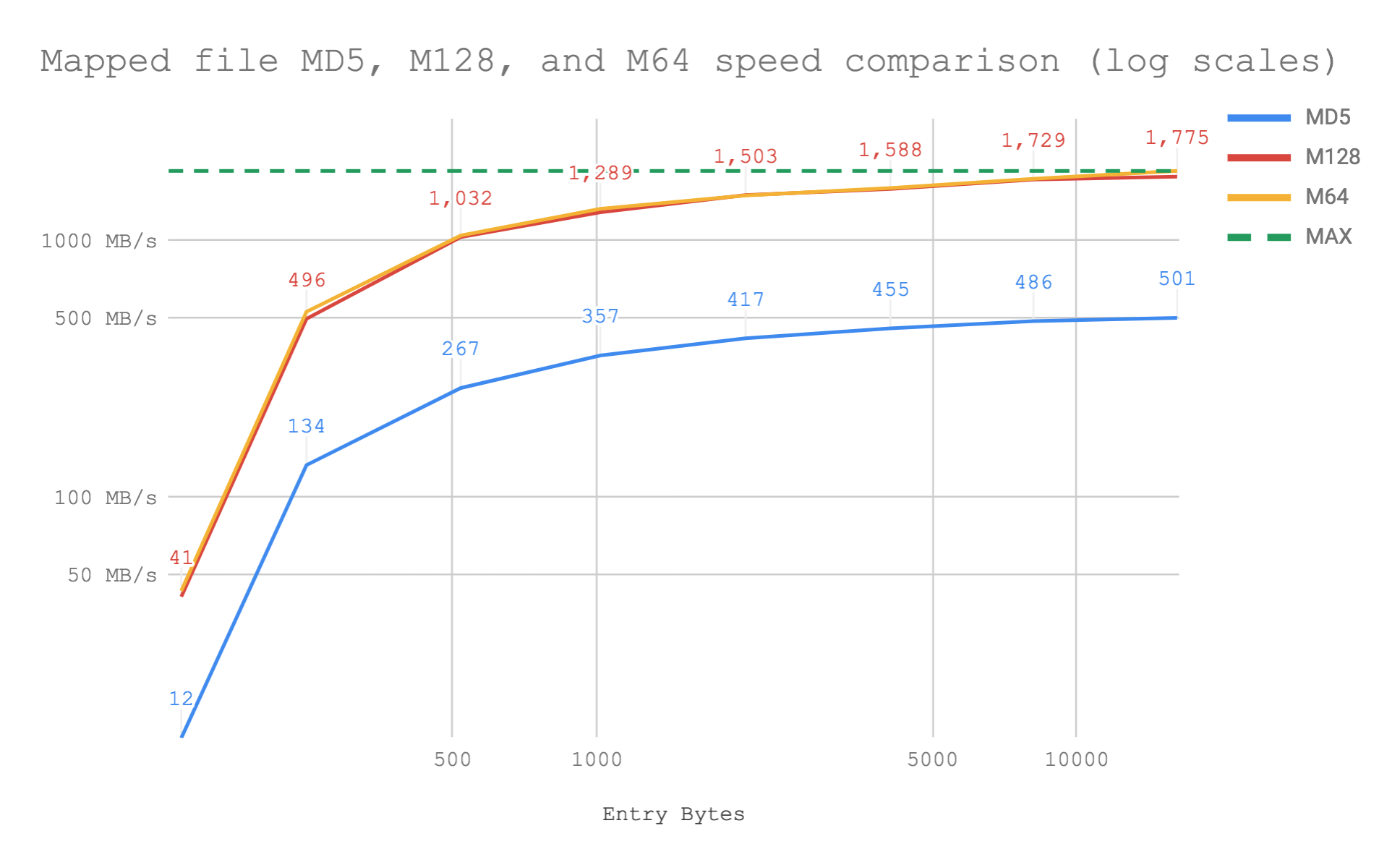
i7-8750H CPU @ 2.20GHz on macOS
We can see the cost of reading data in from a drive when we compare the values of the throughput for every total entry size but our data rates remain comfortably impressive. We are streaming hashes at the rate of 1.7GB/s from disk.
Obviously, a simple hash is a minimal data transformation function but this serves as a baseline to demonstrate that this novel architecture can transform data close to the limits of the hardware while still allowing for high-level abstractions.
Profiling on macOS
As an aside, when developing on a Mac (as we do) Instruments, part of the Apple XCode package, can give you some insight into the performance of your native library. On Linux there are a number of better options, but both embedding Rust in a q process and macOS makes things a little more difficult. Below, I manually run the metro hash on about 1GB of string data and profile it using the Time Profile instrument. While Instruments does not know much about the q binary or symbols as one would expect, our Rust code provides an interesting entry.
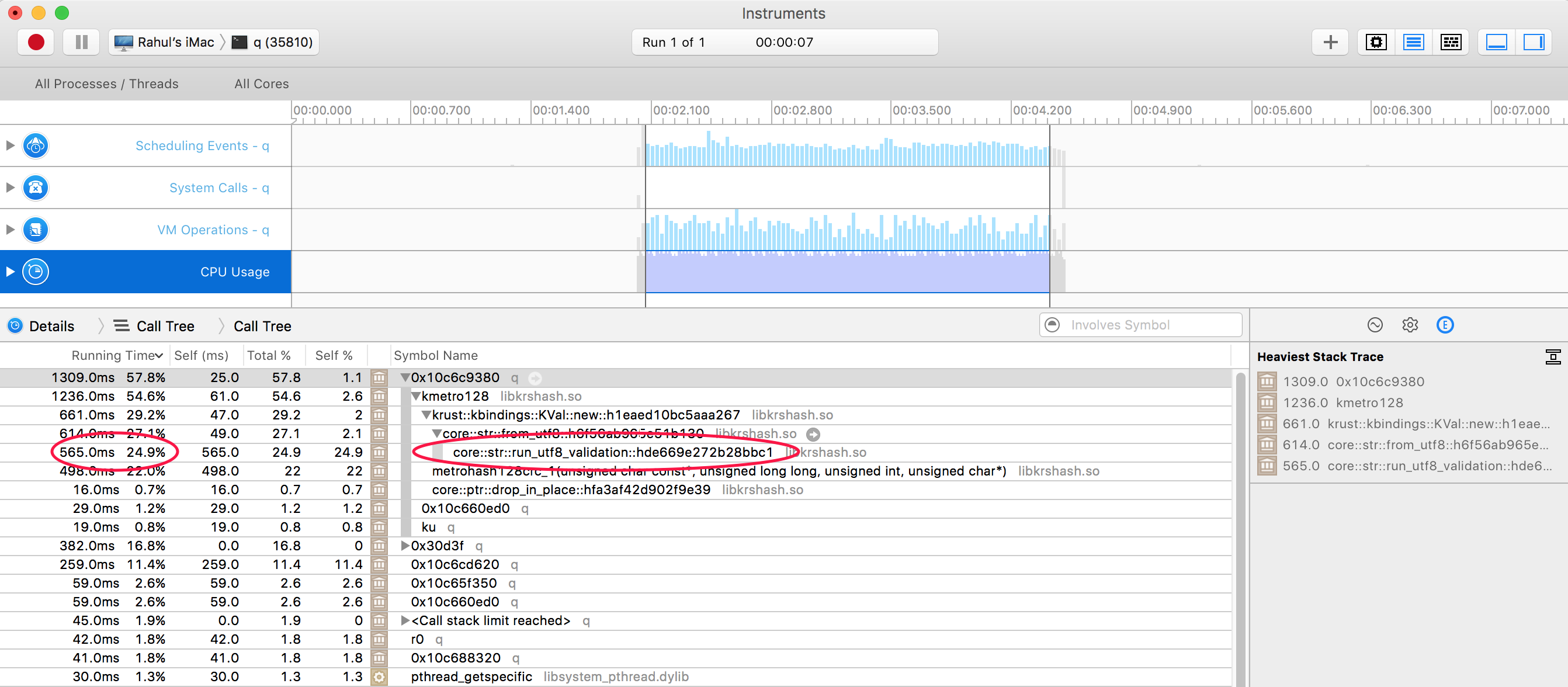
Specifically, we can see that a significant portion of the time is spent in checking the UTF8 string before creating a Rust [rust]&str[/rust]. This is because the Rust to kdb+ binding used by our hasher does a sensible checked conversion as Rust strings must be UTF8 for defined behaviour. However, for this use case the hash really just cares about the byte sequence so we can turn on the [rust]unchecked_utf8[/rust] feature of the crate and remove this safety valve.
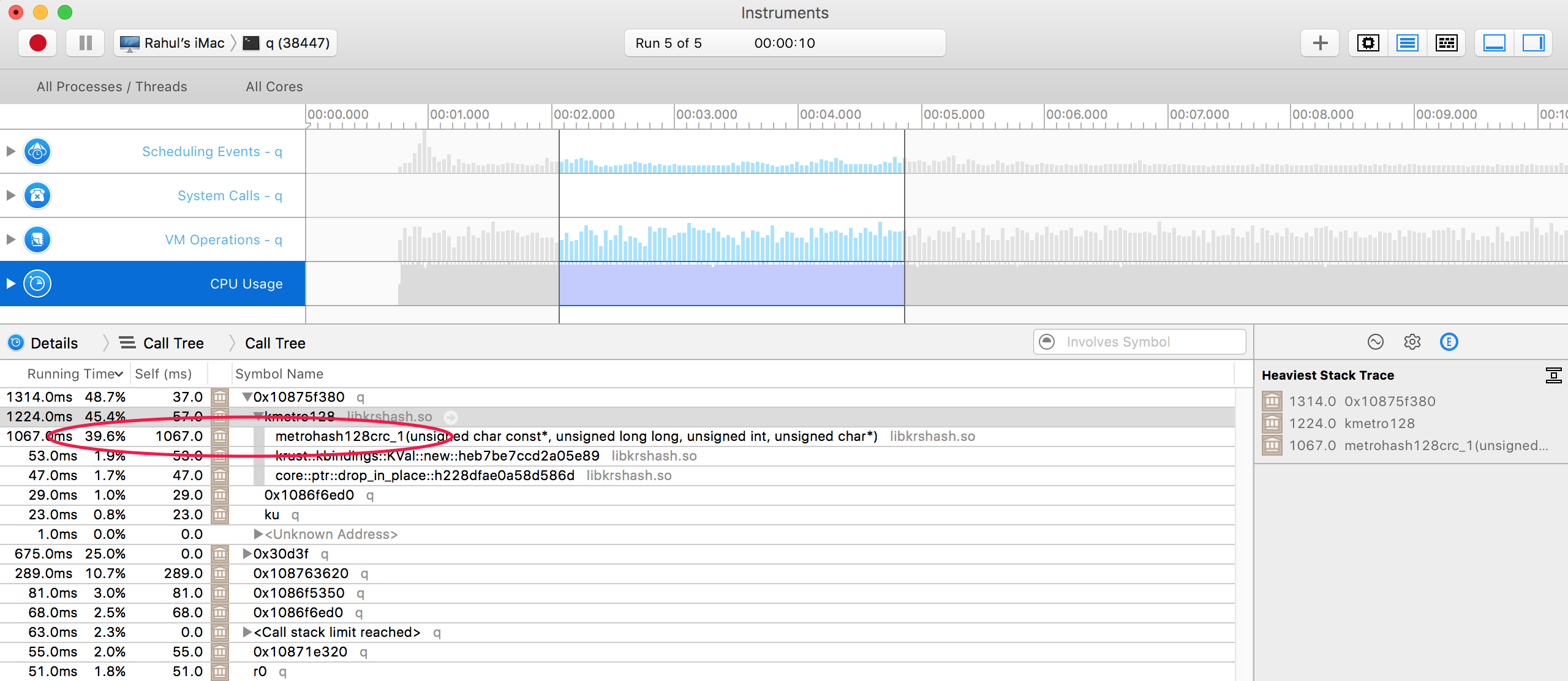
A second pass at Instruments with the feature turned on now shows me that most of the CPU time is spent computing the 128-bit metro hash. As expected, the hash performance as measured in q is between 10% and 15% faster.
One simple thing we can do is to add support for hashing dictionaries in our library. This makes the component easy to use so we can simply pass a sorted key/value set in and generate an identity of the content.
If you look at the repository, you will notice the library includes a few items we have not discussed here.
1. System allocation
By default, Rust will use the jemalloc allocator. However some testing for this use case on macOS shows us that the system memory allocator is around 5% faster in this benchmarked hot loop and gives Instruments visibility on the allocations. This requires the nightly Rust channel and the [rust]alloc_system[/rust] feature.
[rust] #![feature(alloc_system)] extern crate alloc_system;[/rust]
2. Rust errors
We also need to protect the q runtime from any Rust errors e.g. a [rust].unwrap()[/rust] panic bubbling up across the library boundary. As a result you will see each call wrapped.
[rust] let result = catch_unwind(|| {…
panic!(“Oops!”);
});
[/rust]
3. Symbols in Rust binaries
Cargo does not currently support a release build with debug symbols profile. This build configuration is usually used for profilers like Instruments. You will notice the Cargo configuration has this patched into the release build.
[ini] [profile.release] opt-level = 3debug = true
rpath = false
lto = false
debug-assertions = false
codegen-units = 1
[/ini]
4. Parallel processing
Everything we have talked about so far is a single core. There is a lot to cover when exploring [js]rmetro128 each data[/js] vs. [js]rmetro128 peach data[/js] vs. [js].Q.fc[{rmetro128 x}][/js] data as the parallel options introduce a new set of trade offs. In addition, the library also supports non-atomic types mapping lists e.g. lists of strings into lists of hashes and creating a hash identity for the contents of a dictionary. This and more is to be explored in a future post.
In summary, a combination of the excellent and flexible data storage models available in kdb+ and the power and interoperability of Rust backed by the LLVM toolchain allows us to ingest and process data at the rate of > 10 GB/s on a single host. We will be announcing our next generation cyber products built on this novel architecture very soon.
Many thanks to my colleagues rsdy & dc who helped me pull the data together for this experiment.
Reading all the way to the end? You would probably love to work on this. Drop us a note with your GitHub/Bitbucket/GitLab link and/or an old school CV at jobs@redsift.com
Edited 25th-Aug-18: Correction to note that symbols in release binaries is a Cargo issue, not a Rust issue.