Google released 1.9 and we at Red Sift celebrated with Russian pies. When we got back to the keyboard, we could finally finish up something pretty special – Golang is now available on our server-less compute platform, Red Sift, and it is a game-changer.

At Red Sift, most of our platform is written in Go and we love working with it. Yet, we had not officially released support for 3rd party code in Go on our server-less environment. Today, it’s here and we are taking the wraps off.
Settle in, we are going to build a mini Elastic Cloud in Go and run it on our own server-less computing platform.
This ain’t no hello world.
If you are new to Red Sift, our colleague Mike has previously posted on why we exist and what makes us different — I recommend you read it as we are a secure, state-full, server-less platform for when you need to do more than a few admin functions. We are going to turn those features into some serious code.
First, we need some data we can index. Majestic publishes a dense CSV of the top million of the best-indexed sites on a daily refresh. We are going to write some code to index the first thousand from this index and serve an API that we can query for content via free text search.
The challenge, let’s stand up a service that can refresh this data daily, index the domains and the attributes and serve a simple REST+JSON API that is fast enough for type ahead completion. We are going to do this on our server-less platform entirely in Go and we are not going to spin up any thing outside our sandbox — no cheating with external hosted APIs.
Wait, what. If we unpack this we quickly realize that this would need persistence, scheduled tasks, HTTP request/response, some form of index update synchronization and a ton of code and knowhow to essentially recreate a lookalike of a hosted Elasticsearch with our data set.
And we are going to do this in a server-less environment? A few stateless triggers plugged into a remotely hosted propriety ‘data store as a service’ sure, but surely this isn’t possible. At Red Sift, we do exactly this and we use our architecture to deliver customer-facing products that process millions of events on top of it. Here we are going to unpack the box of tricks that makes it possible and why it works well.
On the Red Sift cloud, we provide 2 first-class solutions for storing data.
- A high performance Key Value store that provides long term persistence and a mechanism to cascade data between nodes in a computation graph.
- A POSIX filesystem that has a quota and is provisioned for your instance of an application.
Your data and compute are in a sandbox and the nodes in your compute graph can be designed as pure functions if you use the data from the Key-Value stores. You don’t ask for arbitrary data from an API, it is matched and pumped into your node by Red Sift, and your code, in turn, emits the next batch.
However, purely functional architectures hit their limits and this time around we need our filesystem because we are going to start writing bytes as and when we feel like it. The Red Sift cloud will ensure your nodes have access to redundancy and performance for both stores so you can just work on the code.
To implement our text search, we are going to use the wonderful Golang Bleve library and we are going to back the store with a RocksDB KVStore sitting on our Red Sift provisioned filesystem. We use RocksDB because it allows for a single process writer and multi-process readers which aligns exactly with the architecture of this use case — one node is going to update the text index every day and the other is going to serve an API from it. Red Sift might spawn multiple containers of the reader process to deal with spikes and migrate nodes to other hosts with snapshots of the filesystem. RocksDB’s model lets this work correctly and predictably in all cases.
Bleve and Golang make this work because unlike a JVM based solution (you know who you are), Bleve will open an index in milliseconds and use 10’s of megabytes of RAM allowing Red Sift to spin our nodes up as requests scale and release the resources after traffic for an instance of the Sift has dropped off. Even as we get to the production scale, Bleve and RocksDB can be tuned to maintain a healthy profile that makes good use of compute resources.
First off let’s make sure we have the latest Red Sift SDK for local development.
$> redsift update
Then create an API Sift which simply sets up our scaffolding in the sift.json
$> redsift create ~/mini-elastic (from the menu select the rpc-sift type)
Red Sift DAGs are polyglot, each node runs in a container and every one can be different if we need it to be. In this case, we want a Golang container that has the libraries we need for RocksDB. With a compiled language like Go, we could run it in something much more minimal but for simplicity, we are just using a stock container.
With our content being indexed on a schedule and Bleve doing its magic, we just need to take this index and query from it.
Each node in the DAG is another process that is transparently glued together via IPC if needed. Now we need another node that can serve API requests from a read-only copy of this index. As you can imagine, this node can be scaled up in process count automagically by Red Sift to serve parallel API requests — with Red Sift and RocksDB+Bleve supporting a complementary consistency model, everything will just work correctly. We use the sift.json to describe a DAG, like the one below.
First, lets write our indexing node. This node needs to:
- Get woken up on a schedule as a single instance (Red Sift can do this for us, have a look at the crontab property above)
- Download the CSV
- Open or create an index backed by a RocksDB KVStore
- Scan the rows to create a data structure
- Populate the index (using Bleve batches as that is just faster)
- Clean up
I have moved some bits to utility methods but that is pretty much it. Additionally, we are exporting the Index stats to the front end part of our Sift as a visual clue of progress.
Now, let’s make a service that can take this index and serve some suitably authorized API requests. Red Sift provides an API gateway that will deliver an event to you when an external API call is routed to your Sift. Think of it as a high-level HTTP limiter, authenticator, and router that you don’t have to worry about. The payload gives you all the detail you need to do your own HTTP handling if you want to.
This API node can truly side effect-free, it parses the request, queries Bleve, and spits back the result. Note that the response is via the Red Sift API gateway too, we just emit some data for the request-id we received and all the scattering and gathering of responses is taken care of. We can easily combine the keys we are getting from our text index with structured data and aggregation from our KVStore to compose much more sophisticated functionality — we do precisely this with our own products but in this example, we are focusing on a simple requirement.

Now let us change the query to q=GlobalRank:<50 -TLD:com -TLD:org. Notice the level of query sophistication we are getting out of the box.

Diving deeper into what Bleve can do is way beyond the scope of this post but with the DB code linked to our own codebase, we can customize and optimize indexing at every level based on the data and service we want to provide with no intermediate latency or extra complexity.
So all well and good but how does it get to the internet? Well, check it into GitHub and press the run button on my dashboard. CMD+C my API key and curl.
Whew, so not only does it work, it is blazing fast and available in the real world in under 1 minute. The GitHub for the finished Sift is here. You can fork it and run your own instance in our cloud straight from GitHub and provision private API keys on our dashboard. Red Sift will activate, passivate and cache the containers in your DAG within milliseconds based on request load and resource contention.
To get there, we need the restrictions e.g. only one node in your computation graph can mount a specific large storage bucket with read/write permissions. In exchange, we promise to ensure your files are fast, safe, eventually consistent, and always available to your code via a standard POSIX interface. Our DAG is designed to allow the Red Sift Cloud to reason about data flows at runtime and optimize the nodes that run in the cascade of operations in parallel when data independence allows for it.
So why is this architecture useful?
A lot of our most interesting data sets are private to us as individuals or organizations. At Red Sift, we use our platform to rapidly build cyber security solutions and each customer’s data is explicitly their own. This provides a natural shard that has benefits for both scaling and most critically, security. Customer A’s data is nowhere near Customer B. Mistakes CAN’T happen. The architecture and the sandbox will not allow it. We serve some of the most interesting organizations in the world and we designed our compute platform with this security model baked right into the architecture while still enjoying the benefits of passivating resources when not needed.
In our products, we can index each customers data set individually and hydrate it when they log in.
We don’t need ever scaling DB clusters and indexes that contain 99% dark data at any point in query time. Note that data sharing between accounts and Sifts is possible and better for other use cases, but as a developer, you have to opt into it, and that is a topic for another post.
If you want to go bigger, our default free QoS levels will likely not be enough to get to indexing gigabytes and terabytes of data so talk to us about your needs and we can likely increase your quotas so you can play.
So is this ready for production?
We use precisely this with our own award-winning cyber security product OnDMARC. OnDMARC looks like a ‘normal’ Cloud SaaS product but it is a deep data+computation tool with APIs, a React front-end and enterprise features like SSO support, and role-based end-user access that is built and served entirely on the only server-less environment that can pull it off, our own.
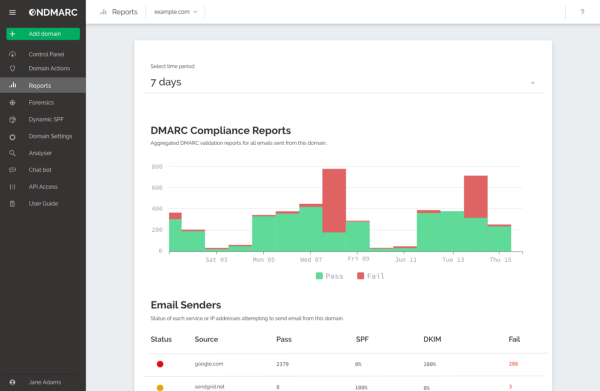
The bulk of OnDMARC is in NodeJS with a few nodes in our computation graph now built-in Go. Any realistic commercial project needs a mix of technologies to make the most of the developers and libraries available — we are no different. Yet with Red Sift all this interoperates with minimal latency and 0 (yes, zero, I promise) lines of glue code in our server-less environment. If you want to know how this works under the hood, you will have to dive into our docs.
The best part is that our customers benefit from the speed and security that comes with our unique architecture and there is nothing stopping you from doing the same.
If you liked this, follow us on Twitter or take a look at how we are trying to change the game with our products. If you are responsible for IT security at your organization and you don’t know about DMARC, you need to read up. If you cut code, talk to us about building solutions on our platform and solving our customer’s needs.
Start your free ONDMARC trial today
Interested in getting DMARC set up easily and quickly for your business? Start your free 14-day trial today!